Data Anonymization
Data anonymization and privacy are of paramount importance in the context of studies involving human subjects, protected sites, and biodiversity. The disclosure of identifiable, sensitive, or legally protected data can harm participants. Implementing de-identification strategies and adopting access control measures are vital for preventing these risks, as they safeguard against the linkage of sensitive attributes with specific participants and locations.
Human Subjects' Data
Before initiating any research involving human participants, consult the Office of Research's Human Subject Department for Institutional Review Board (IRB) protocols and required training.
Sensitive data encompasses any information that, if disclosed, could lead to harm, legal issues, or damage to a subject's reputation, whether or not it is legally protected. Examples of such data include:
- Criminal or illegal activities, such as drug use.
- Mental health.
- Sexual behaviors.
- Data concerning minors or other vulnerable groups.
Legally protected data are subject to legal restrictions such as the Family Education Rights and Privacy Act (FERPA) which includes educational data records like grades, and the Health Insurance Portability and Accountability Act (HIPAA), including medical records.
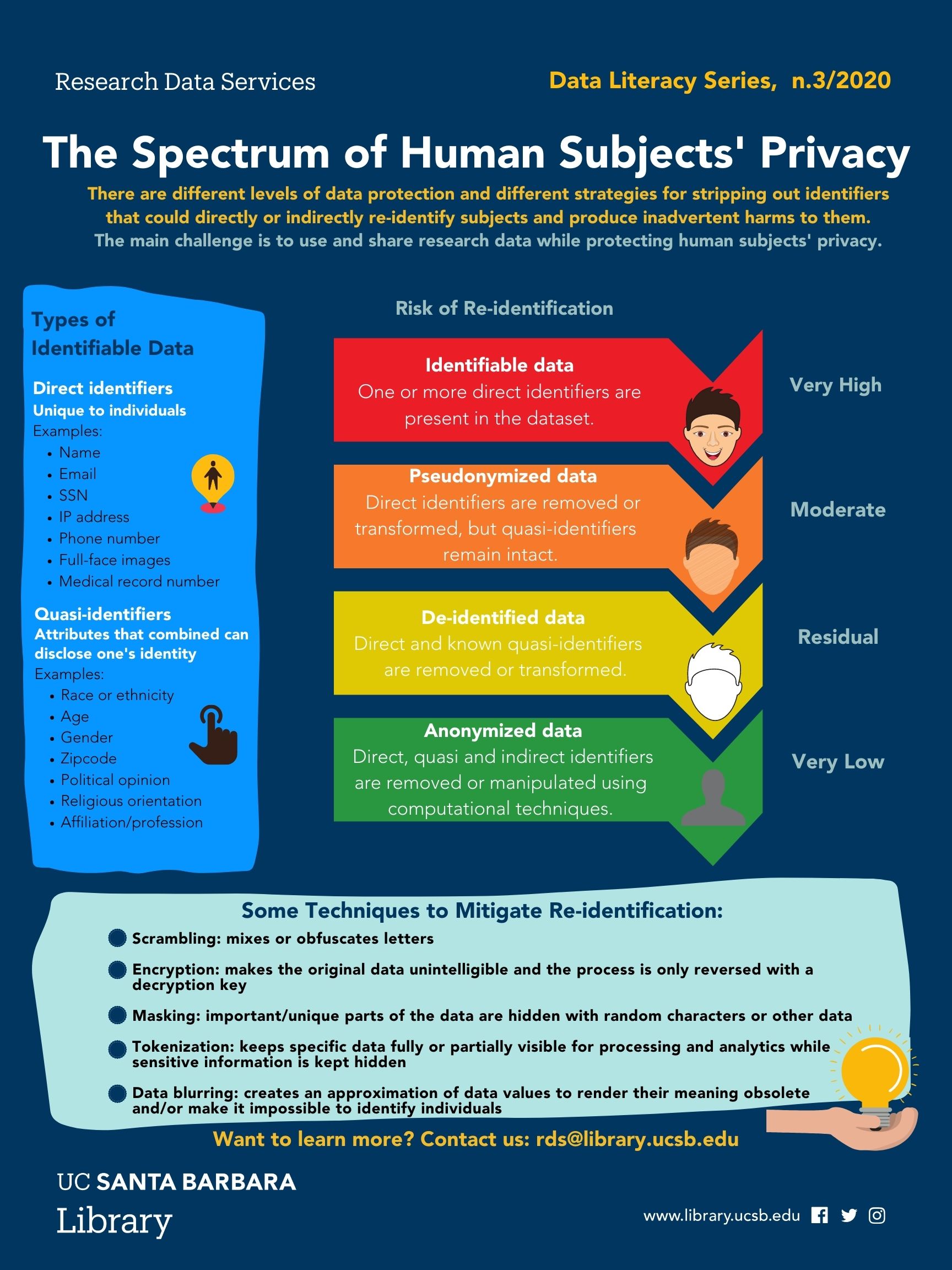
Sharing human subjects' data presents a significant challenge due to the potential for the disclosure (unauthorized release) of individuals' identities, either directly or indirectly:
- Direct identifiers or Personally Identifiable Information (PII), including items like name, address, social security number, and phone number.
- Indirect identifiers, such as zip code, birthdate, education, and race/ethnicity, which, when combined, may uniquely identify an individual.
It is noteworthy that other Information within the dataset when matched with external data sources like social media, administrative records, or public datasets, could result in the identification of an individual. Therefore these need also to be addressed and protected from disclosure.
Anonymization - Qualitative Data
When safeguarding qualitative data like transcribed interviews, it is advisable to employ pseudonyms or general descriptions to modify any identifiable details instead of removing the information altogether.
It's crucial to assess the extent of anonymity necessary, which should align with the agreements established in the informed consent procedure. Advance planning and establishing clear guidelines can be a much more effective way of collecting data that accurately represents the research process and participants' inputs.
- Only collect necessary data; for instance, avoid requesting full names and other identifiable information if they won't be used.
- Plan anonymization during transcription or initial write-up (with exceptions for longitudinal studies).
- Maintain consistent pseudonyms or replacements throughout the project and publications.
- Use 'search and replace' techniques carefully to avoid unintended changes.
- Clearly indicate replacements with brackets.
- Safely keep the unedited (raw) data for internal use and preservation for the period specified in your IRB.
- Create an anonymization log for all changes and store it separately and safely.
- Consider redacting statements that pose a risk of harm or disclosure.
Anonymization - Quantitative Data
The process of anonymizing quantitative data entails eliminating or consolidating variables or reducing the level of precision or detail associated with a variable. You may accomplish data anonymization using programmatic methods and open tools. Some common techniques include:
- Aggregation: This involves reducing a variable's precision or detailed characteristics, such as removing the last four digits of a zip code and converting it into a county name.
- Top-coding: It restricts the upper range of a variable, for example, specifying the top income category as "200,000 and above." By only revealing the lower limit, it prevents users from identifying individuals with very high incomes, like those making $300,000 per year.
- Variable collapsing or combination: This method merges data from multiple variables into a single category, which is especially useful when there are too few subjects in each of the initial categories.
- Bracketing or Categorization: This process transforms continuous variables into categorical ones by reporting a variable range rather than its precise value, such as indicating a range of years for the number of years spent in an institution.
Additionally, we recommend researchers:
- Use weighted data to generate output
- Avoid submitting tables with small cell sizes (i.e., cells with fewer than 5 respondents)
- Restrict cross-tabular analysis to two or three dimensions
- Be cautious when using small subgroups or small areas
- Avoid listings of cases with outliers
Researchers should also consider methods and statistical disclosure control methods for risk measurement and data utility assessment. risk
Species Data
Remember that sensitive data also includes data that, if disclosed without precaution, may infringe upon ethical agreements and threaten the ownership, representation, and existence of vulnerable communities, protected lands, and species.
See: Chapman AD (2020) Current Best Practices for Generalizing Sensitive Species Occurrence Data. Copenhagen: GBIF Secretariat. https://doi.org/10.15468/doc-5jp4-5g10.
The UCSB Libray's Research Data Services Department can help you navigate some tools and methods for data anonymization. Schedule a consultation with us: rds@library.ucsb.edu.
Data Protection
Before sharing data involving human subjects, researchers should ensure that the dataset poses a low risk of re-identifying subjects. If your data contains legally protected or sensitive information or removing identifiers would diminish its utility, you should consider sharing it through repositories that support access restrictions and impose limitations for data re-use and re-sharing. Additionally, the agreements made with participants through the Institutional Review Board (IRB) can also impose limitations on the extent to which data involving human subjects can be shared.
Research data should be considered as open as possible and as restricted as necessary. Depending on the project needs, researchers should consider sharing data:
- Under licensing agreements
- Applying differential privacy
- Via data enclave
- As metadata only
Sensitive Government-licensed Datasets
Research involving government-licensed datasets containing personally identifiable information (PII) or personal health information (PHI), such as those from the Institute for Education Sciences or the Department of Health, requires formal institutional approval to ensure compliance with security requirements. Facilitated by the Office of Technology and Industry Alliances (TIA), this process ensures that all the necessary security controls are implemented before receiving the data and maintained throughout its use. Visit the UCSB Information Technology’s page on Final Signoff Process for Government Licensed Datasets for more information.
Recommended Resources
-
The Spectrum of Human Subjects' Privacy
-
Data ONE - Best Practices
-
Identify Data Sensitivity
-
Storing Sensitive Data at UCSB
- The Secure Compute Research Environment (SCRE) is a private, secure, virtual environment for researchers to remotely analyze sensitive data, create research results, and output results and analyses.
-
Current Best Practices for Generalizing Sensitive Species Occurrence Data
- The Global Biodiversity Information Facility (GBIF) guide for dealing with sensitive primary species occurrence data.